RAG: indexing, retrieval, and evaluation
An end-to-end Retrieval Augmented Generation reference built on LangChain, OpenAI, and Chroma. Three pipelines share configuration through a shared module, and the evaluation pipeline grades answers three complementary ways. Source on GitHub.
Indexing
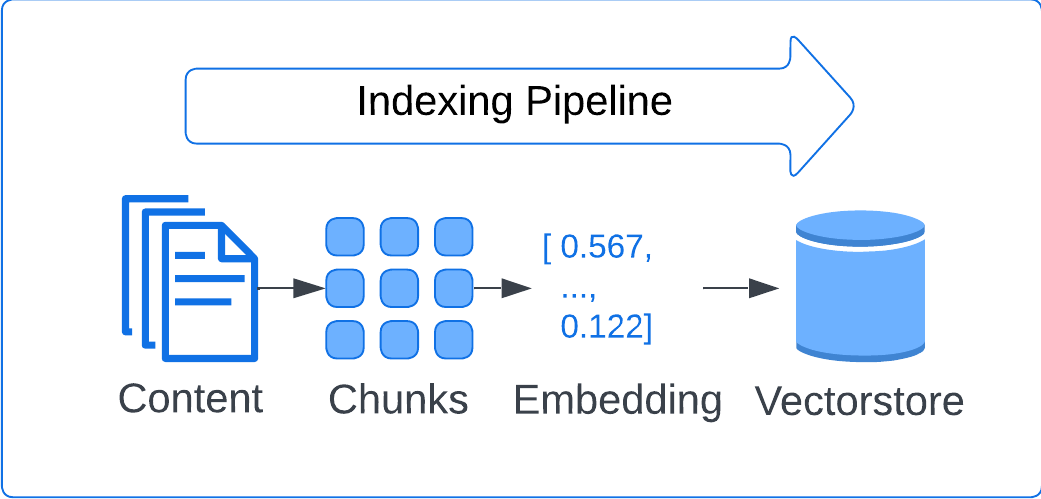
The indexing pipeline loads a web document, splits it into chunks with overlap, embeds each chunk with OpenAI's text-embedding-3-small, and persists the result to a local Chroma vectorstore.
Retrieval and generation
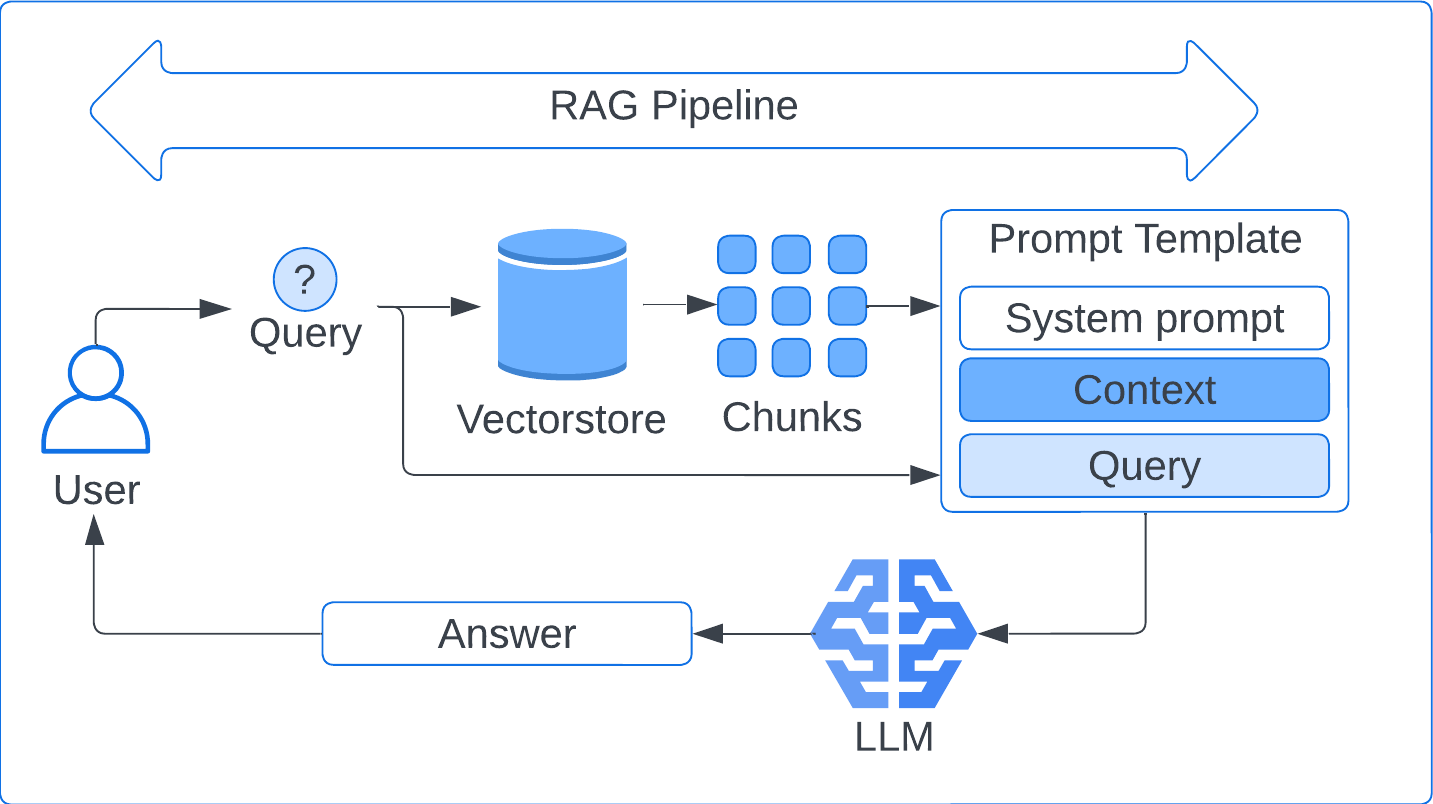
The RAG pipeline takes a user question, retrieves the top similar chunks from the vectorstore, and feeds them into a chat model along with a constrained prompt. The chain composes as retriever → prompt → model → string output, idiomatic LangChain.
Evaluation: three lenses
A separate evaluation pipeline grades each answer three complementary ways. The lenses disagree often, which is exactly when evaluation pays off.
- Code-based. Deterministic, free, instant. Length bounds, keyword presence, structural rules. Catches format regressions; blind to meaning.
- Model-as-judge. A separate LLM scores relevance and faithfulness against the retrieved context. Catches semantic problems the code checks cannot, at the cost of an extra API call.
- Human-grade. The ground truth the other two only approximate. Auto-skips when run non-interactively.
What I would change for production
The repo README spells out the migration path candidly. Each topic carries an honest tradeoff.
- Observability. LangSmith tracing so each retrieval and generation becomes an inspectable span.
- Cost guards. Rate limiting, token budget caps, and embedding-call dedupe for unchanged source documents.
- Async indexing. A background worker for large corpora so the request path stays snappy.
- Citations. Returning which retrieved chunks contributed to each answer for trust and debugging.
- Tests. Unit tests for chain composition; a smoke test against a tiny fixed corpus.
- Schema versioning. Versioning the collection by embedding model and chunk size as the vectorstore evolves.
Run it yourself
Clone the repo, set OPENAI_API_KEY, install the requirements, and run the three pipelines in sequence. Full instructions live in the README on GitHub.